!pip3 install ufal.udpipe spacy nltk scikit-learn==0.24.2
!pip3 install gensim==4.0.1 wordcloud nagisa conllu tensorflow==2.5.0 tensorflow-estimator==2.5.010 Text as data
Update planned: R Tidytext
At the time of writing this chapter for the published book, quanteda was our package of choice for text analysis in R. We now think that the tidytext package is easier to learn for students who have just leared the tidyverse data wrangling package. For this reason, we are planning to rewrite this chapter using that package. See the relevant github issue for more information.
Abstract. This chapter shows how you can analyze texts that are stored as a data frame column or variable using functions from the package quanteda in R and the package sklearn in Python and R. Please see Chapter 9 for more information on reading and cleaning text.
Keywords. Text as Data, Document-Term Matrix
Objectives:
- Create a document-term matrix from text
- Perform document and feature selection and weighting
- Understand and use more advanced representations such as n-grams and embeddings
10.1 The Bag of Words and the Term-Document Matrix
Before you can conduct any computational analysis of text, you need to solve a problem: computations are usually done on numerical data – but you have text. Hence, you must find a way to represent the text by numbers. The document-term matrix (DTM, also called the term-document matrix or TDM) is one common numerical representation of text. It represents a corpus (or set of documents) as a matrix or table, where each row represents a document, each column represents a term (word), and the numbers in each cell show how often that word occurs in that document.
As an example, Example 10.1 shows a DTM made from two lines from the famous poem by Mary Angelou. The resulting matrix has two rows, one for each line; and 11 columns, one for each unique term (word). In the columns you see the document frequencies of each term: the word “bird” occurs once in each line, but the word “with” occurs only in the first line (text1) and not in the second (text2).
In R, you can use the dfm function from the quanteda package (Benoit et al. 2018). This function can take a vector or column of texts and transforms it directly into a DTM (which quanteda actually calls a document-feature matrix, hence the function name dfm). In Python, you achieve the same by creating an object of the CountVectorizer class, which has a fit_transform function.
10.1.1 Tokenization
In order to turn a corpus into a matrix, each text needs to be tokenized, meaning that it must be split into a list (vector) of words. This seems trivial, as English (and most western) text generally uses spaces to demarcate words. However, even for English there are a number of edge cases. For example, should “haven’t” be seen as a single word, or two?
Example 10.2 shows how Python and R deal with the sentence “I haven’t seen John’s derring-do”. For Python, we first use CountVectorizer.build_tokenizer to access the built-in tokenizer. As you can see in the first line of input, this tokenizes “haven’t” to haven, which of course has a radically different meaning. Moreover, it silently drops all single-letter words, including the 't, 's, and I.
In the box “Tokenizing in Python” below, we therefore discuss some alternatives. For instance, the TreebankWordTokenizer included in the nltk package is a more reasonable tokenizer and splits “haven’t” into have and n't, which is a reasonable outcome. Unfortunately, this tokenizer assumes that text has already been split into sentences, and it also includes punctuation as tokens by default. To circumvent this, we can introduce a custom tokenizer based on the Treebank tokenizer, which splits text into sentences (using nltk.sent_tokenize) – see the box for more details.
For R, we simply call the tokens function from the quanteda package. This keeps haven't and John's as a single word, which is probably less desirable than splitting the words but at least better than outputting the word haven.
As this simple example shows, even a relatively simple sentence is tokenized differently by the tokenizers considered here (and see the box on tokenization in Python). Depending on the research question, these differences might or might not be important. However, it is always a good idea to check the output of this (and other) preprocessing steps so you understand what information is kept or discarded.
Note that for languages such as Chinese, Japanese, and Korean, which do not use spaces to delimit words, the story is more difficult. Although a full treatment is beyond the scope of this book, Example 10.3 shows a small example of tokenizing Japanese text, in this case the famous haiku “the sound of water” by Bashō. The default tokenizer in quanteda actually does a good job, in contrast to the default Python tokenizer that simply keeps the whole string as one word (which makes sense since this tokenizer only looks for whitespace or punctuation). For Python the best bet is to use a custom package for tokenizing Japanese, such as the nagisa package. This package contains a tokenizer which is able to tokenize the Japanese text, and we could use this in the CountVectorizer much like we used the TreebankWordTokenizer for English earlier. Similarly, with heavily inflected languages such as Hungarian or Arabic, it might be better to use preprocessing tools developed specifically for these languages, but treating those is beyond the scope of this book.
10.1.2 The DTM as a Sparse Matrix
Example 10.4 shows a more realistic example. It downloads all US “State of the Union” speeches and creates a document-term matrix from them. Since the matrix is now easily too large to print, both Python and R simply list the size of the matrix. R lists \(85\) documents (rows) and \(17999\) features (columns), and Python reports that its size is \(85\times17185\). Note the difference in the number of columns (unique terms) due to the differences in tokenization as discussed above.
In Example 10.5 we show how you can look at the content of the DTM. First, we show the overall term and document frequencies of each word, where we showcase words at different frequencies. Unsurprisingly, the word the tops both charts, but further down there are minor differences. In all cases, the highly frequent words are mostly functional words like them or first. More informative words such as investments are by their nature used much less often. Such term statistics are very useful to check for noise in the data and get a feeling of the kind of language that is used. Second, we take a look at the frequency of these same words in four speeches from Truman to Obama. All use words like the and first, but none of them talk about defrauded – which is not surprising, since it was only used once in all the speeches in the corpus.
However, the words that ranked around 1000 in the top frequency are still used in less than half of the documents. Since there are about 17000 even less frequent words in the corpus, you can imagine that most of the document-term matrix consists of zeros. The output also noted this sparsity in the first output above. In fact, R reports that the dtm is \(91\%\) sparse, meaning 91% percent of all entries are zero. Python reports a similar figure, namely that there are only just under 150000 non-zero entries out of a possible \(8\times22219\), which boils down to a 92% sparse matrix.
Note that to display the matrix we turned it from a sparse matrix representation into a dense matrix. Briefly put, in a dense matrix, all entries are stored as a long list of numbers, including all the zeros. In a sparse matrix, only the non-zero entries and their location are stored. This conversion (using the function as.matrix and the method todense respectively), however, was only performed after selecting a small subset of the data. In general, it is very inefficient to store and work with the matrix in a dense format. For a reasonably large corpus with tens of thousands of documents and different words, this can quickly run to billions of numbers, which can cause problems even on modern computers and is, moreover, very inefficient. Because sparsity values are often higher than 99%, using a sparse matrix representation can easily reduce storage requirements by a hundred times, and in the process speed up calculations by reducing the number of entries that need to be inspected. Both quanteda and scikit-learnstore DTMs as sparse matrices by default, and most analysis tools are able to deal with sparse matrices very efficiently (see, however, Section 11.4.1 for problems with machine learning on sparse matrices in R).
A final note on the difference between Python and R in this example. The code in R is much simpler and produces nicer results since it also shows the words and the speech names. In Python, we wrote our own helper function to create the frequency statistics which is built into the R quanteda package. These differences between Python and R reflect a pattern that is true in many (but not all) cases: in Python libraries such as numpyand scikit-learnare setup to maximize performance, while in R a library such as quanteda or tidyverse is more geared towards ease of use. For that reason, the DTM in Python does not “remember” the actual words, it uses the index of each word, so it consumes less memory if you don’t need to use the actual words in e.g. a machine learning setup. R, on the other hand, stores the words and also the document IDs and metadata in the DFM object. This is easier to use if you need to look up a word or document, but it consumes (slightly) more memory.
10.1.3 The DTM as a “Bag of Words”
As you can see already in these simple examples, the document-term matrix discards quite a lot of information from text. Specifically, it disregards the order or words in a text: “John fired Mary” and “Mary fired John” both result in the same DTM, even though the meaning of the sentences is quite different. For this reason, a DTM is often called a bag of words, in the sense that all words in the document are simply put in a big bag without looking at the sentences or context of these words.
Thus, the DTM can be said to be a specific and “lossy” representation of the text, that turns out to be quite useful for certain tasks: the frequent occurrence of words like “employment”, “great”, or “I” might well be good indicators that a text is about the economy, is positive, or contains personal expressions respectively. As we will see in the next chapter, the DTM representation can be used for many different text analyses, from dictionaries to supervised and unsupervised machine learning.
Sometimes, however, you need information that is encoded in the order of words. For example, in analyzing conflict coverage it might be quite important to know who attacks whom, not just that an attack took place. In the Section 10.3 we will look at some ways to create a richer matrix-representation by using word pairs. Although it is beyond the scope of this book, you can also use automatic syntactic analysis to take grammatical relations into account as well. As is always the case with automatic analyses, it is important to understand what information the computer is looking at, as the computer cannot find patterns in information that it doesn’t have.
10.1.4 The (Unavoidable) Word Cloud
One of the most famous text visualizations is without doubt the word cloud. Essentially, a word cloud is an image where each word is displayed in a size that is representative of its frequency. Depending on preference, word position and color can be random, depending on word frequency, or in a decorative shape.
Word clouds are often criticized since they are (sometimes) pretty but mostly not very informative. The core reason for that is that only a single aspect of the words is visualized (frequency), and simple word frequency is often not that informative: the most frequent words are generally uninformative “stop words” like “the” and “I”.
For example, Example 10.6 shows the word cloud for the state of the union speeches downloaded above. In R, this is done using the quanteda function textplot_wordcloud. In Python we need to work a little harder, since it only has the counts, not the actual words. So, we sum the DTM columns to get the frequency of each word, and combine that with the feature names (words) from the CountVectorized object cv. Then we can create the word cloud and give it the frequencies to use. Finally, we plot the cloud and remove the axes.
Example 10.6 Word cloud of the US State of the Union corpus
def wordcloud(dfm, vectorizer, **options):
freq_dict = dict(
zip(vectorizer.get_feature_names_out(), dfm.sum(axis=0).tolist()[0])
)
wc = WordCloud(**options)
return wc.generate_from_frequencies(freq_dict)
wc = wordcloud(d, cv, background_color="white")
plt.imshow(wc)
plt.axis("off")plt.show()
textplot_wordcloud(d, max_words=200)
The results from Python and R look different at first – for one thing, R is nice and round but Python has more colors! However, if you look at the cloud you can see both are not very meaningful: the largest words are all punctuation or words like “a”, “and”, or “the”. You have to look closely to find words like “federal” or “security” that give a hint on what the texts were actually about.
10.2 Weighting and Selecting Documents and Terms
So far, the DTMs you made in this chapter simply show the count of each word in each document. Many words, however, are not informative for many questions. This is especially apparent if you look at a word cloud, essentially a plot of the most frequent words in a corpus (set of documents).
More formally, a document-term matrix can be seen as a representation of data points about documents: each document (row) is represented as a vector containing the count per word (column). Although it is a simplification compared to the original text, an unfiltered document-term matrix contains a lot of relevant information. For example, if a president uses the word “terrorism” more often than the word “economy”, that could be an indication of their policy priorities.
However, there is also a lot of noise crowding out this signal: as seen in the word cloud in the previous section the most frequent words are generally quite uninformative. The same holds for words that hardly occur in any document (but still require a column to be represented) and noisy “words” such as punctuation or technical artifacts like HTML code.
This section will discuss a number of techniques for cleaning a corpus or document-term matrix in order to minimize the amount of noise: removing stop words, cleaning punctuation and other artifacts, and trimming and weighting. As a running example in this section, we will use a collection of tweets from US president Donald Trump. Example 10.7 shows how to load these tweets into a data frame containing the ID and text of the tweets. As you can see, this dataset contains a lot of non-textual features such as hyperlinks and hash tags as well as regular punctuation and stop words. Before we can start analyzing this data, we need to decide on and perform multiple cleaning steps such as detailed below.
Please note that although tweets are perhaps overused as a source of scientific information, we use them here because they nicely exemplify issues around non-textual elements such as hyperlinks. See Chapter 12 for information on how to use the Twitter and other APIs to collect your own data.
10.2.1 Removing stopwords
A first step in cleaning a DTM is often stop word removal. Words such as “a” and “the” are often called stop words, i.e. words that do not tell us much about the content. Both quanteda and scikit-learninclude built-in lists of stop words, making it very easy to remove the most common words. Example 10.8 shows the result of specifying “English” stop words to be removed for both packages.
Example 10.8 Simple stop word removal
cv = CountVectorizer(
stop_words=stopwords.words("english"), tokenizer=mytokenizer.tokenize
)
d = cv.fit_transform(tweets.text)
wc = wordcloud(d, cv, background_color="white")
plt.imshow(wc)
plt.axis("off")plt.show()
d = corpus(tweets) %>%
tokens(remove_punct=T) %>%
dfm() %>%
dfm_remove(stopwords("english"))
textplot_wordcloud(d, max_words=100)
Note, however, that it might seem easy to list words like “a” and “and”, but as it turns out there is no single well-defined list of stop words, and (as always) the best choice depends on your data and your research question.
Linguistically, stop words are generally function words or closed word classes such as determiner or pronoun, with closed classes meaning that while you can coin new nouns, you can’t simply invent new determiners or prepositions. However, there are many different stop word lists around which make different choices and are compatible with different kinds of preprocessing. The Python word cloud in Example 10.8 shows a nice example of the importance of matching stopwords with the used tokenization: a central “word” in the cloud is the contraction ’s. We are using the NLTK tokenizer, which splits ’s from the word it was attached to, but the scikit-learnstop word list does not include that term. So, it is important to make sure that the words created by the tokenization match the way that words appear in the stop word list.
As an example of the substantive choices inherent in using a stop word lists, consider the word “will”. As an auxiliary verb, this is probably indeed a stop word: for most substantive questions, there is no difference whether you will do something or simply do it. However, “will” can also be a noun (a testament) and a name (e.g. Will Smith). Simply dropping such words from the corpus can be problematic; see Section 10.3.4 for ways of telling nouns and verbs apart for more fine-grained filtering.
Moreover, some research questions might actually be interested in certain stop words. If you are interested in references to the future or specific modalities, the word might actually be a key indicator. Similarly, if you are studying self-expression on Internet forums, social identity theory, or populist rhetoric, words like “I”, “us” and “them” can actually be very informative.
For this reason, it is always a good idea to understand and inspect what stop word list you are using, and use a different one or customize it as needed (see also Nothman, Qin, and Yurchak 2018). Example 10.9 shows how you can inspect and customize stop word lists. For more details on which lists are available and what choices these lists make, see the package documentation for the stopwords package in Python (part of NLTK) and R (part of quanteda)
10.2.2 Removing Punctuation and Noise
Next to stop words, text often contains punctuation and other things that can be considered “noise” for most research questions. For example, it could contain emoticons or emoji, Twitter hashtags or at-mentions, or HTML tags or other annotations.
In both Python and R, we can use regular expressions to remove (parts of) words. As explained above in Section 9.2, regular expressions are a powerful way to specify (sequences of) characters which are to be kept or removed. You can use this, for example, to remove things like punctuation, emoji, or HTML tags. This can be done either before or after tokenizing (splitting the text into words): in other words, we can clean the raw texts or the individual words (tokens).
In general, if you only want to keep or remove certain words, it is often easiest to do so after tokenization using a regular expression to select the words to keep or remove. If you want to remove parts of words (e.g. to remove the leading “#” in hashtags) it is easiest to do that before tokenization, that is, as a preprocessing step before the tokenization. Similarly, if you want to remove a term that would be split by the tokenization (such as hyperlinks), if can be better to remove them before the tokenization occurs.
Example 10.10 shows how we can use regular expressions to remove noise in Python and R. For clarity, it shows the result of each processing step on a single tweet that exemplifies many of the problems described above. To better understand the tokenization process, we print the tokens in that tweet separated by a vertical bar (|). As a first cleaning step, we will use a regular expression to remove hyperlinks and HTML entities like & from the untokenized texts. Since both hyperlinks and HTML entities are split over multiple tokens, it would be hard to remove them after tokenization.
Regular expressions are explained fully in Section 9.2, so we will keep the explanation short: the bar | splits the pattern in two parts, i.e. it will match if it finds either of the subpatterns. The first pattern looks for the literal text http, followed by an optional s and the sequence ://. Then, it takes all non-whitespace characters it finds, i.e. the pattern ends at the next whitespace or end of the text. The second pattern looks for an ampersand (&) followed by one or more letters (\\w+), followed by a semicolon (;). This matches HTML escapes like & for an ampersand.
In the next step, we process the tokenized text to remove every token that is either a stopword or does not start with a letter. In Python, this is done by using a list comprehension ([process(item) for item in list]) for tokenizing each document; and a nested list comprehension for filtering each token in each document. In R this is not needed as the tokens_\* functions are vectorized, that is, they directly run over all the tokens.
Comparing R and Python, we see that the different tokenization functions mean that #trump is removed in R (since it is a token that does not start with a letter), but in Python the tokenization splits the # from the name and the resulting token trump is kept. If we would have used a different tokenizer for Python (e.g. the WhitespaceTokenizer) this would have been different again. This underscores the importance of inspecting and understanding the results of the specific tokenizer used, and to make sure that subsequent steps match these tokenization choices. Concretely, with the TreebankWordtokenizer we would have had to also remove hashtags at the text level rather than the token level.
Example 10.11 Cleaning the whole corpus and making a tag cloud
def do_nothing(x):
return x
tokenized = [
WhitespaceTokenizer().tokenize(text) for text in tweets.text.values
]
tokens = [
[t.lower() for t in tokens if regex.match("#", t)] for tokens in tokenized
]
cv = CountVectorizer(tokenizer=do_nothing, lowercase=False)
dtm_emoji = cv.fit_transform(tokens)
wc = wordcloud(dtm_emoji, cv, background_color="white")
plt.imshow(wc)
plt.axis("off")plt.show()
dfm_cleaned = tweets %>%
corpus() %>%
tokens() %>%
tokens_keep("^#", valuetype="regex") %>%
dfm()
colors = RColorBrewer::brewer.pal(8, "Dark2")
textplot_wordcloud(dfm_cleaned, max_words=100,
min_size = 1, max_size=4, random_order=TRUE,
random_color= TRUE, color=colors)
As a final example, Example 10.11 shows how to filter tokens for the whole corpus, but rather than removing hashtags it keeps only the hashtags to produce a tag cloud. In R, this is mostly a pipeline of quanteda functions to create the corpus, tokenize, keep only hashtags, and create a DFM. To spice up the output we use the RColorBrewer package to set random colors for the tags. In Python, you can see that we now have a nested list comprehension, where the outer loop iterates over the texts and the inner loop iterates over the tokens in each text. Next, we make a do_nothing function for the vectorizer since the results are already tokenized. Note that we need to disable lowercasing as otherwise it will try to call .lower() on the token lists.
10.2.3 Trimming a DTM
The techniques above both drop terms from the DTM based on specific choices or patterns. It can also be beneficial to trim a DTM by removing words that occur very infrequently or overly frequently. For the former, the reason is that if a word only occurs in a very small percentage of documents it is unlikely to be very informative. Overly frequent words, for example occurring in more than half or 75% of all documents, function basically like stopwords for this corpus. In many cases, this can be a result of the selection strategy. If we select all tweets containing “Trump”, the word Trump itself is no longer informative about their content. It can also be that some words are used as standard phrases, for example “fellow Americans” in state of the union speeches. If every president in the corpus uses those terms, they are no longer informative about differences between presidents.
Example 10.12 shows how you can use the relative document frequency to trim a DTM in Python and R. We keep only words with a document frequency of between 0.5% and 75%.
Although these are reasonable numbers every choice depends on the corpus and the research question, so it can be a good idea to check which words are dropped.
Note that dropping words that occur almost never should normally not influence the results that much, since those words do not occur anyway. However, trimming a DTM to e.g. at least 1% document frequency often radically reduces the number of words (columns) in the DTM. Since many algorithms have to assign weights or parameters to each word, this can provide a significant improvement in computing speed or memory use.
10.2.4 Weighting a DTM
The DTMs created above all use the raw frequencies as cell values. It can also be useful to weight the words so more informative words have a higher weight than less informative ones. A common technique for this is tf\(\cdot\)idf weighting. This stands for term frequency \(\cdot\) inverse document frequency and weights each occurrence by its raw frequency (term frequency) corrected for how often it occurs in all documents (inverse document frequency). In a formula, the most common implementation of this weight is given as follows:
\(tf\cdot idf(t,d)=tf(t,d)\cdot idf(t)=f_{t,d}\cdot -\log \frac{n_t}{N}\)
Where \(f_{t,d}\) is the frequency of term \(t\) in document \(d\), \(N\) is the total number of documents, and \(n_t\) is the number of documents in which term \(t\) occurs. In other words, the term frequency is weighted by the negative log of the fraction of documents in which that term occurs. Since \(\log(1)\) is zero, terms that occur in every document are disregarded, and in general the less frequent a term is, the higher the weight will be.
tf\(\cdot\)idf weighting is a fairly common technique and can improve the results of subsequent analyses such as supervised machine learning. As such, it is no surprise that it is easy to apply this in both Python and R, as shown in Example 10.13. This example uses the same data as Example 10.4 above, so you can compare the resulting weighted values with the results reported there. As you can see, the tf\(\cdot\)idf weighting in both languages have roughly the same effect: very frequent terms such as the are made less important compared to less frequent words such as submit. For example, in the raw frequencies for the 1965 Johnson speech, the occurred 355 times compared to submit only once. In the weighted matrix, the weight for submit is four times as low as the weight for the.
There are two more things to note if you compare the examples from R and Python. First, to make the two cases somewhat comparable we have to use two options for R, namely to set the term frequency to proportional (scheme_tf='prop'), and to add smoothing to the document frequencies (smooth=1). Without those options, the counts for the first columns would all be zero (since they occur in all documents, and \(\log \frac{85}{85}=0\)), and the other counts would be greater than one since they would only be weighted, not normalized.
Even with those options the results are still different (in details if not in proportions), mainly because R normalizes the frequencies before weighting, while Python normalizes after the weighting. Moreover, Python by default uses L2 normalization, meaning that the length of the document vectors will be one, while R uses L1 normalization, that is, the row sums are one (before weighting). Both R and Python have various parameters to control these choices which are explained in their respective help pages. However, although the differences in absolute values look large, the relative effect of making more frequent terms less important is the same, and the specific weighting scheme and options will probably not matter that much for the final results. However, it is always good to be aware of the specific options available and try out which work best for your specific research question.
10.3 Advanced Representation of Text
The examples above all created document-term matrices where each column actually represents a word. There is more information in a text, however, than pure word counts. The phrases: the movie was not good, it was in fact quite bad and the movie was not bad, in fact it was quite good have exactly the same word frequencies, but are quite different in meaning. Similarly, the new kings of York and the kings of New York refer to very different people.
Of course, in the end which aspect of the meaning of a text is important depends on your research question: if you want to know the sentiment about the movie, it is important to take a word like “not” into account; but if you are interested in the topic or genre of the review, or the extremity of the language used, this might not be relevant.
The core idea of this section is that in many cases this information can be captured in a DTM by having the columns represent different information than just words, for example word combinations or groups of related words. This is often called feature engineering, as we are using our domain expertise to find the right features (columns, independent variables) to capture the relevant meaning for our research question. If we are using other columns than words it is also technically more correct to use the name document-feature matrix, as quanteda does, but we will stick to the most common name here and simply continue using the name DTM.
10.3.1 \(n\)-grams
The first feature we will discuss are n-grams. The simplest case is a bigram (or 2-gram), where each feature is a pair of adjacent words. The example used above, the movie was not bad, will yield the following bigrams: the-movie, movie-was, was-not, and not-bad. Each of those bigrams is then treated as a feature, that is, a DTM would contain one column for each word pair.
As you can see in this example, we can now see the difference between not-bad and not-good. The downside of using n-grams is that there are many more unique word pairs than unique words, so the resulting DTM will have many more columns. Moreover, there is a bigger data scarcity problem, as each of those pairs will be less frequent, making it more difficult to find sufficient examples of each to generalize over.
Although bigrams are the most frequent use case, trigrams (3-grams) and (rarely) higher-order n-grams can also be used. As you can imagine, this will create even bigger DTMs and worse data scarcity problems, so even more attention must be paid to feature selection and/or trimming.
Example 10.14 shows how n-grams can be created and used in Python and R. In Python, you can pass the ngram_range=(n, m) option to the vectorizer, while R has a tokens_ngrams(n:m) function. Both will post-process the tokens to create all n-grams in the range of n to m. In this example, we are asking for unigrams (i.e., the words themselves), bigrams and trigrams of a simple example sentence. Both languages produce the same output, with R separating the words with an underscore while Python uses a simple space.
Example 10.15 shows how you can generate n-grams for a whole corpus. In this case, we create a DTM of the state of the union matrix with all bigrams included. A glance at the frequency table for all words containing government shows that, besides the word itself and its plural and possessive forms, the bigrams include compound words (federal and local government), phrases with the government as subject (the government can and must), and nouns for which the government is an adjective (government spending and government programs).
You can imagine that including all these words as features will add many possibilities for analysis of the DTM which would not be possible in a normal bag-of-words approach. The terms local and federal government can be quite important to understand policy positions, but for e.g. sentiment analysis a bigram like not good would also be insightful (but make sure “not” is not on your stop word list!).
10.3.2 Collocations
A special case of n-grams are collocations. In the strict corpus linguistic sense of the word, collocations are pairs of words that occur more frequently than expected based on their underlying occurrence. For example, the phrase crystal clear presumably occurs much more often than would be expected by chance given how often crystal and clear occur separately. Collocations are important for text analysis since they often have a specific meaning, for example because they refer to names such as New York or disambiguate a term like sound in sound asleep, a sound proposal, or loud sound.
Example 10.16 shows how to identify the most “surprising” collocations using R and Python. For Python, we use the gensim package which we will also use for topic modeling in Section 11.5. This package has a Phrases class which can identify the bigrams in a list of tokens. In R, we use the textstat_collocations function from quanteda. These packages each use a different implementation: gensim uses pointwise mutual information, i.e. how much information about finding the second word does seeing the first word give you? Quanteda estimates an interaction parameter in a loglinear model. Nonetheless, both methods give very similar results, with Saddam Hussein, the Iron Curtain, Al Qaida, and red tape topping the list for each.
The next block demonstrates how to use these collocations in further processing. In R, we filter the collocations list on \(lambda>8\) and use the tokens_compound function to compound bigrams from that list. As you can see in the term frequencies filtered on “Hussein”, the regular terms (apart from the possessive) are removed and the compounded term now has 26 occurrences. For Python, we use the PhraseTransformer class, which is an adaptation of the Phrases class to the scikit-learnmethodology. After setting a standard threshold of 0.7, we can use fit_transform to change the tokens. The term statistics again show how the individual terms are now replaced by their compound.
10.3.3 Word Embeddings
A recent addition to the text analysis toolbox are word embeddings. Although it is beyond the scope of this book to give a full explanation of the algorithms behind word embeddings, they are relatively easy to understand and use at an intuitive level.
The first core idea behind word embeddings is that the meaning of a word can be expressed using a relatively small embedding vector, generally consisting of around 300 numbers which can be interpreted as dimensions of meaning. The second core idea is that these embedding vectors can be derived by scanning the context of each word in millions and millions of documents.
These embedding vectors can then be used as features or DTM columns for further analysis. Using embedding vectors instead of word frequencies has the advantages of strongly reducing the dimensionality of the DTM: instead of (tens of) thousands of columns for each unique word we only need hundreds of columns for the embedding vectors. This means that further processing can be more efficient as fewer parameters need to be fit, or conversely that more complicated models can be used without blowing up the parameter space. Another advantage is that a model can also give a result for words it never saw before, as these words most likely will have an embedding vector and so can be fed into the model. Finally, since words with similar meanings should have similar vectors, a model fit on embedding vectors gets a “head start” since the vectors for words like “great” and “fantastic” will already be relatively close to each other, while all columns in a normal DTM are treated independently.
The assumption that words with similar meanings have similar vectors can also be used directly to extract synonyms. This can be very useful, for example for (semi-)automatically expanding a dictionary for a concept. Example 10.17 shows how to download and use pre-trained embedding vectors to extract synonyms. First, we download a very small subset of the pre-trained Glove embedding vectors1, wrapping the download call in a condition to only download it when needed.
Then, for Python, we use the excellent support from the gensim package to load the embeddings into a KeyedVectors object. Although not needed for the rest of the example, we create a Pandas data frame from the internal embedding values so the internal structure becomes clear: each row is a word, and the columns (in this case 50) are the different (semantic) dimensions that characterize that word according to the embeddings model. This data frame is sorted on the first dimension, which shows that negative values on that dimension are related to various sports. Next, we switch back to the KeyedVectors object to get the most similar words to the word fraud, which is apparently related to similar words like bribery and corruption but also to words like charges and alleged. These similarities are a good way to (semi-)automatically expand a dictionary: start from a small list of words, find all words that are similar to those words, and if needed manually curate that list. Finally, we use the embeddings to solve the “analogies” that famously showcase the geometric nature of these vectors: if you take the vector for king, subtract the vector for man and add that for woman, the closest word to the resulting vector is queen. Amusingly, it turns out that soccer is a female form of football, probably showing the American cultural origin of the source material.
For R, there was less support from existing packages so we decided to use the opportunity to show both the conceptual simplicity of embeddings vectors and the power of matrix manipulation in R. Thus, we directly read in the word vector file which has a head line and then on each line a word followed by its 50 values. This is converted to a matrix with the row names showing the word, which we normalize to (Euclidean) length of one for each vector for easier processing. To determine similarity, we take the cosine distance between the vector representing a word with all other words in the matrix. As you might remember from algebra, the cosine distance is the dot product between the vectors normalized to have length one (just like Pearson’s product–moment correlation is the dot product between the vectors normalized to z-scores per dimension). Thus, we can simply multiply the normalized target vector with the normalized matrix to get the similarity scores. These are then sorted, renamed, and the top values are taken using the basic functions from Chapter 6. Finally, analogies are solved by simply adding and subtracting the vectors as explained above, and then listing the closest words to the resulting vector (excluding the words in the analogy itself).
10.3.4 Linguistic Preprocessing
A final technique to be discussed here is the use of linguistic preprocessing steps to enrich and filter a DTM. So far, all techniques discussed here are language independent. However, there are also many language-specific tools for automatically enriching text developed by computational linguistics communities around the world. Two techniques will be discussed here as they are relatively widely available for many languages and easy and quick to apply: Part-of-speech tagging and lemmatizing.
In part-of-speech tagging or POS-tagging, each word is enriched with information on its function in the sentence: verb, noun, determiner etc. For most languages, this can be determined with very high accuracy, although sometimes text can be ambiguous: in one famous example, the word flies in fruit flies is generally a noun (fruit flies are a type of fly), but it can also be a verb (if fruit could fly). Although there are different sets of POS tags used by different tools, there is broad agreement on the core set of tags listed in Table 10.1.
POS tags are useful since they allow us for example to analyze only the nouns if we care about the things that are discussed, only the verbs if we care about actions that are described, or only the adjectives if we care about the characteristics given to a noun. Moreover, knowing the POS tag of a word can help disambiguate it. For example, like as a verb (I like books) is generally positive, but like as a preposition (a day like no other) has no clear sentiment attached.
Lemmatizing is a technique for reducing each word to its root or lemma (plural: lemmata). For example, the lemma of the verb reads is (to) read and the lemma of the noun books is book. Lemmatizing is useful since for most of our research questions we do not care about these different conjugations of the same word. By lemmatizing the texts, we do not need to include all conjugations in a dictionary, and it reduces the dimensionality of the DTM – and thus also the data scarcity.
Note that lemmatizing is related to a technique called stemming, which removes known suffixes (endings) from words. For example, for English it will remove the “s” from both reads and books. Stemming is much less sophisticated than lemmatizing, however, and will trip over irregular conjugations (e.g. are as a form of to be) and regular word endings that look like conjugations (e.g. virus will be stemmed to viru). English has relatively simple conjugations and stemming can produce adequate results. For morphologically richer languages such as German or French, however, it is strongly advised to use lemmatizing instead of stemming. Even for English we would generally advise lemmatization since it is so easy nowadays and will yield better results than stemming.
For Example 10.18, we use the UDPipe natural language processing toolkit (Straka and Straková 2017), a “Pipeline” that parses text into “Universal Dependencies”, a representation of the syntactic structure of the text. For R, we can immediately call the udpipe function from the package of the same name. This parses the given text and returns the result as a data frame with one token (word) per row, and the various features in the columns. For Python, we need to take some more steps ourselves. First, we download the English models if they aren’t present. Second, we load the model and create a pipeline with all default settings, and use that to parse the same sentence. Finally, we use the conllu package to read the results into a form that can be turned into a data frame.
In both cases, the resulting tokens clearly show some of the potential advantages of linguistic processing: the lemma column shows that it correctly deals with irregular verbs and plural forms. Looking at the upos (universal part-of-speech) column, John is recognized as a proper name (PROPN), bought as a verb, and knives as a noun. Finally, the head_token_id and dep_rel columns represent the syntactic information in the sentence: “Bought” (token 2) is the root of the sentence, and “John” is the subject (nsubj) while “knives” is the object of the buying.
The syntactic relations can be useful if you need to differentiate between who is doing something and whom it was done to. For example, one of the authors of this book used syntactic relations to analyze conflict coverage, where there is an important difference between attacking and getting attacked (Van Atteveldt et al. 2017). However, in most cases you probably don’t need this information and analyzing dependency graphs is relatively complex. We would advise you to almost always consider lemmatizing and tagging your texts, as lemmatizing is simply so much better than stemming (especially for languages other than English), and the part-of-speech can be very useful for analyzing different aspects of a text.
If you only need the lemmatizer and tagger, you can speed up processing by setting udpipe(.., parser='none') (R) or setting the third argument to Pipeline (the parser) to Pipeline.NONE (Python). Example 10.19 shows how this can be used to extract only the nouns from the most recent state of the union speeches, create a DTM with these nouns, and then visualize them as a word cloud. As you can see, these words (such as student, hero, childcare, healthcare, and terrorism), are much more indicative of the topic of a text than the general words used earlier. In the next chapter we will show how you can further analyze these data, for example by analyzing usage patterns per person or over time, or using an unsupervised topic model to cluster words into topics.
Example 10.19 Nouns used in the most recent State of the Union addresses
def get_nouns(text):
result = conllu.parse(pipeline.process(text))
for sentence in result:
for token in sentence:
if token["upos"] == "NOUN":
yield token["lemma"]
parser = Pipeline.NONE
pipeline = Pipeline(m, "tokenize", Pipeline.DEFAULT, Pipeline.NONE, "conllu")
tokens = [list(get_nouns(text)) for text in sotu.text[-5:]]
cv = CountVectorizer(tokenizer=lambda x: x, lowercase=False, max_df=0.7)
dtm_verbs = cv.fit_transform(tokens)
wc = wordcloud(dtm_verbs, cv, background_color="white")
plt.imshow(wc)
plt.axis("off")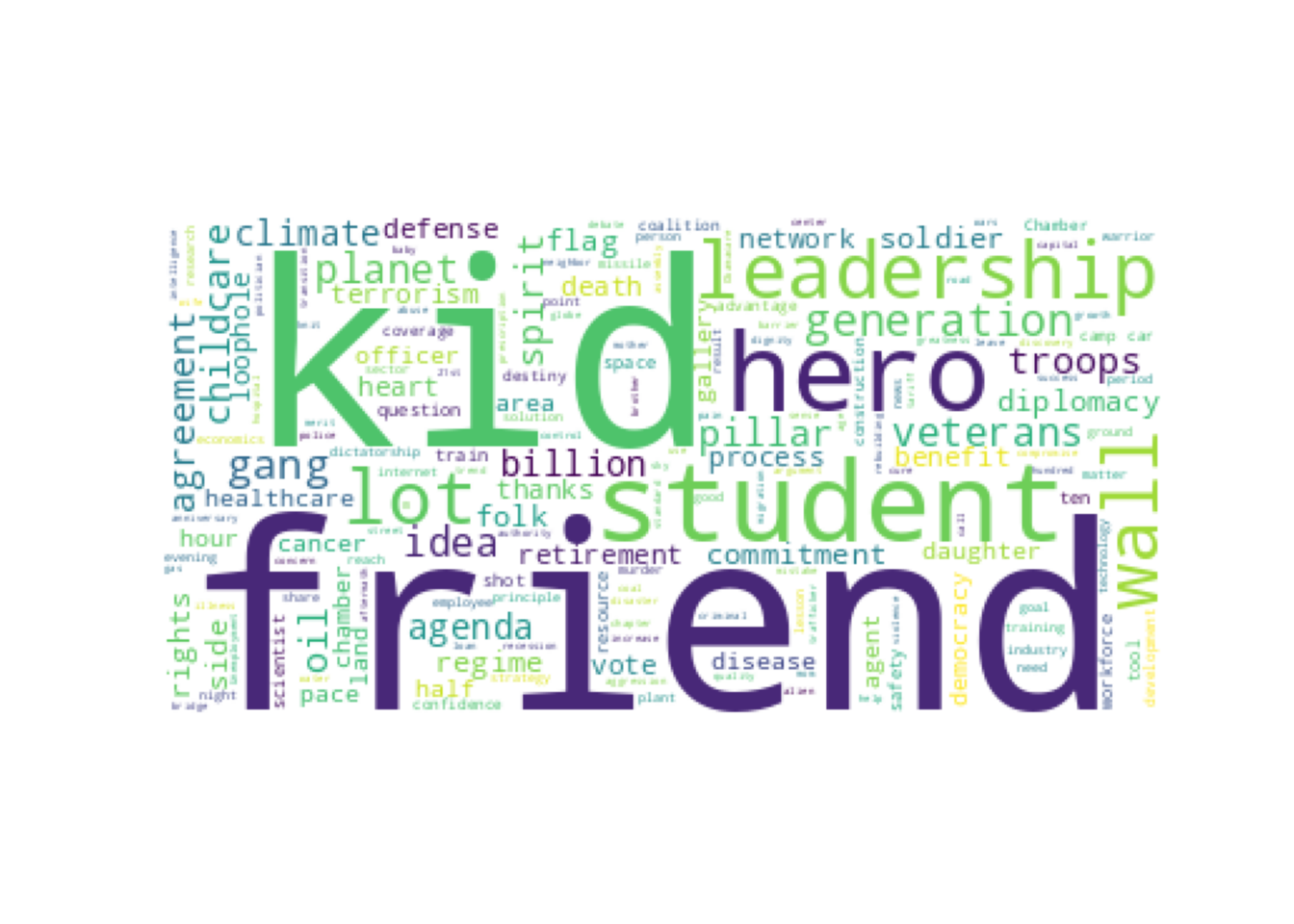
tokens = sotu %>%
top_n(5, Date) %>%
udpipe("english", parser="none")
nouns = tokens %>%
filter(upos == "NOUN") %>%
group_by(doc_id) %>%
summarize(text=paste(lemma, collapse=" "))
nouns %>%
corpus() %>%
tokens() %>%
dfm() %>%
dfm_trim(max_docfreq=0.7,docfreq_type="prop")%>%
textplot_wordcloud(max_words=50)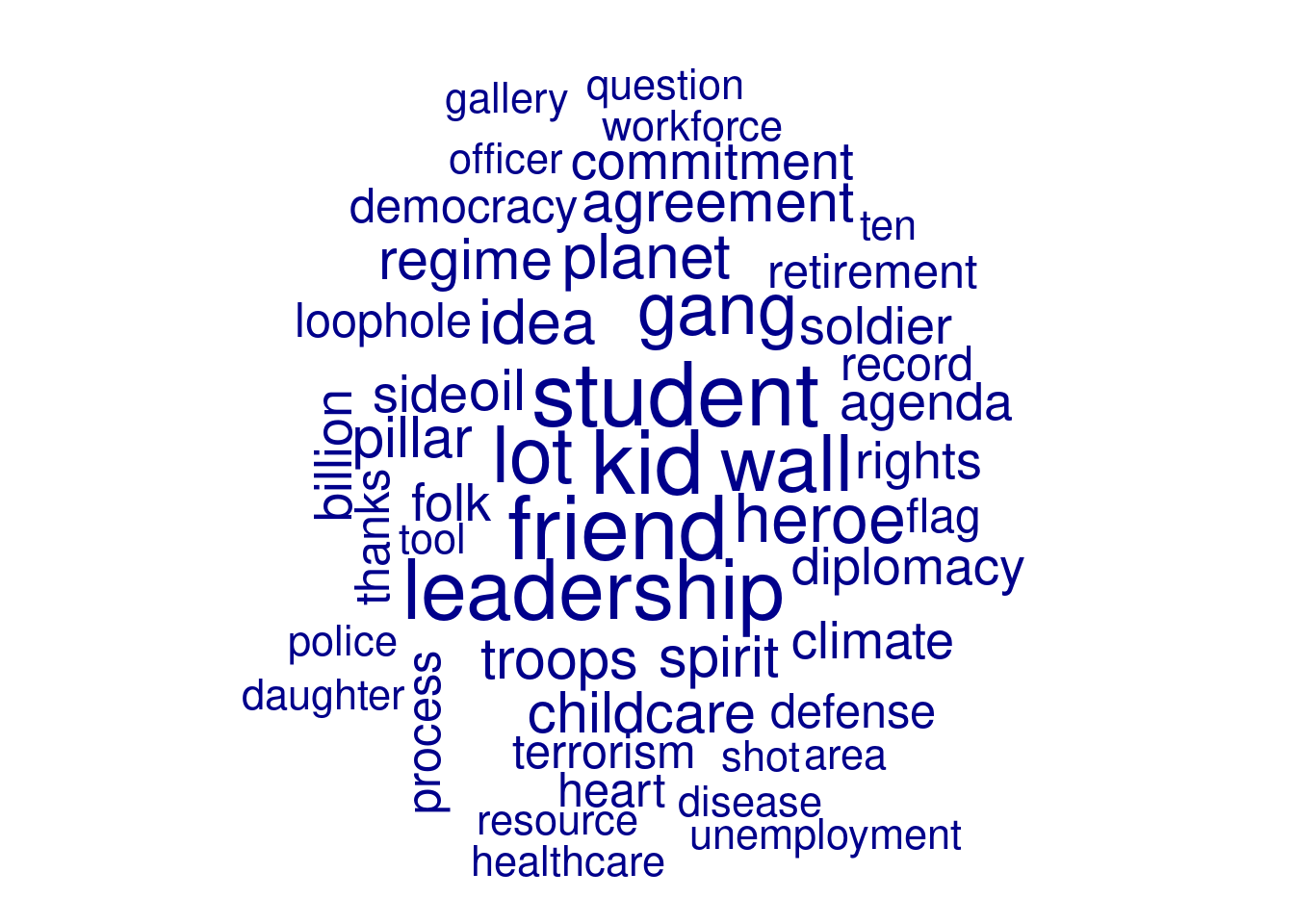
As an alternative to UDPipe, you can also use Spacy, which is another free and popular natural language toolkit. It is written in Python, but the spacyr package offers an easy way to use it from R. For R users, installation of spacyr on MacOS and Linux is easy, but note that on Windows there are some additional steps, see cran.r-project.org/web/packages/spacyr/readme/README.html for more details.
Example 10.20 shows how you can use Spacy to analyze the proverb “all roads lead to Rome” in Spanish. In the first block, the Spanish language model is downloaded (this is only needed once). The second block loads the language model and parses the sentence. You can see that the output is quite similar to UDPipe, but one additional feature is the inclusion of Named Entity Recognition: Spacy can automatically identify persons, locations, organizations and other entities. In this example, it identifies “Rome” as a location. This can be very useful to extract e.g. all persons from a newspaper corpus automatically. Note that in R, you can use the quanteda function as.tokens to directly use the Spacy output in quanteda.
As you can see, nowadays there are a number of good and relatively easy to use linguistic toolkits that can be used. Especially Stanza (Qi et al. 2020) is also a very good and flexible toolkit with support for multiple (human) languages and good integration especially with Python. If you want to learn more about natural language processing, the book Speech and Language Processing by Jurafsky and Martin is a very good starting point (Jurafsky and Martin (2009))2.
10.4 Which Preprocessing to Use?
This chapter has shown how to create a DTM and especially introduced a number of different steps that can be used to clean and preprocess the DTM before analysis. All of these steps are used by text analysis practitioners and in the relevant literature. However, no study ever uses all of these steps on top of each other. This of courses raises the question of how to know which preprocessing steps to use for your research question.
First, there are a number of things that you should (almost) always do. If your data contains noise such as boilerplate language, HTML artifacts, etc., you should generally strip these out before proceeding. Second, text almost always has an abundance of uninformative (stop) words and a very long tail of very rare words. Thus, it is almost always a good idea to use a combination of stop word removal, trimming based on document frequency, and/or tf.idf weighting. Note that when using a stop word list, you should always manually inspect and/or fine-tune the word list to make sure it matches your domain and research question.
The other steps such as n-grams, collocations, and tagging and lemmatization are more optional but can be quite important depending on the specific research. For this (and for choosing a specific combination of trimming and weighting), it is always good to know your domain well, look at the results, and think whether you think they make sense. Using the example given above, bigrams can make more sense for sentiment analysis (since not good is quite different from good), but for analyzing the topic of texts it may be less important.
Ultimately, however, many of these questions have no good theoretical answer, and the only way to find a good preprocessing “pipeline” for your research question is to try many different options and see which works best. This might feel like “cheating” from a social science perspective, since it is generally frowned upon to just test many different statistical models and report on what works best. There is a difference, however, between substantive statistical modeling where you actually want to understand the mechanisms, and technical processing steps where you just want the best possible measurement of an underlying variable (presumably to be used in a subsequent substantive model). Lin (2015) uses the analogy of the mouse trap and the human condition: in engineering you want to make the best possible mouse trap, while in social science we want to understand the human condition. For the mouse trap, it is OK if it is a black box for which we have no understanding of how it works, as long as we are sure that it does work. For the social science model, this is not the case as it is exactly the inner workings we are interested in.
Technical (pre)processing steps such as those reviewed in this chapter are primarily engineering devices: we don’t really care how something like tfc.idf works, as long as it produces the best possible measurement of the variables we need for our analysis. In other words, it is an engineering challenge, not a social science research question. As a consequence, the key criterion by which to judge these steps is validity, not explainability. Thus, it is fine to try out different options, as long as you validate the results properly. If you have many different choices to evaluate against some metric such as performance on a subsequent prediction task, using the split-half or cross-validation techniques discussed in chapter Chapter 8 are also relevant here to avoid biasing the evaluation.
The full embedding models can be downloaded from https://nlp.stanford.edu/projects/glove/. To make the file easier to download, we took only the 10000 most frequent words of the smallest embeddings file (the 50 dimension version of the 6B tokens model). For serious applications you probably want to download the larger files, in our experience the 300 dimension version usually gives good results. Note that the files on that site are in a slightly different format which lacks the initial header line, so if you want to use other vectors for the examples here you can convert them with the
glove2word2vecfunction in the gensim package. For R, you can also simply omit theskip=1argument as apart from the header line the formats are identical.↩︎See web.stanford.edu/~jurafsky/slp3/ for their draft of a new edition, which is (at the time of writing) free to download.↩︎